La Famille BERT et les Transformers
Qu'est-ce que BERT ? Quel lien avec les transformers ? Pourquoi les utilise-t-on ? Comment ?



Une petite révolution
Ces dernières années, la recherche en Intelligence Artificielle a été complètement transformée par une avancée technologique: les transformers. Avant de comprendre comment et pourquoi cette transformation s'est opérée, prenons un instant pour examiner comment la recherche en IA évalue une avancée technique.
La recherche en IA se concentre depuis plusieurs années sur les tâches dites difficiles de la compréhension du monde: les systèmes de recommandation de contenu, l'extraction d'informations à partir de textes (discipline du traitement automatique du langage ou Natural Language Processing, NLP en anglais) ou d'image (Vision par ordinateur ou Computer Vision, CV) et plus récemment également sur l'audio. Chacune de ces discipline a déterminé un certain nombre de tâches d'extraction d'information que l'on cherche à faire effectuer à un programme, comme par exemple :
- La détection d'objets (localiser une personne dans une image), la segmentation d'image (identifier la portion de l'image représentant une route), la classification d'images (dire si il s'agit d'une photo de lave-linge ou d'un frigo) en vision par ordinateur
- La classification de texte (dire si un texte est positif ou négatif), l'extraction d'entités nommées d'un texte (identifier les noms de personnes, d'organisation, de pays etc.), le résumé de texte ou la réponse aux questions sur un texte dans le domaine du traitement du langage naturel. Pour chacune de ces tâches ont été déterminés des jeux de données de référence et des méthodologies d'évaluation de l'efficacité d'un algorithme à réaliser la tâche en question.
Jusque là, les meilleures performances étaient atteintes par des modèles spécialisés pour chaque tâche précise, et l'entraînement de chaque modèle était un défi en soi. C'est dans ce contexte que les Transformers ont apporté une petite révolution: en 2018 dans l'article présentant BERT (BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding), Google présente une méthodologie de pré-entraînement et de spécialisation qui, appliquée à une architecture à base de Transformers, surpasse l'état de l'art sur chacune des tâches classiques de traitement du langage naturel, et ce d'une marge conséquente.
Pourquoi les Transformers et BERT fonctionnent-ils si bien ?
La contribution du papier de BERT a été dans un premier temps de combiner avec succès plusieurs techniques déjà connues:
- Les Transformers, une architecture de Deep Learning qui avait déjà fait ses preuves. Cette architecture est basée sur le mécanisme d'attention, qui permet de prendre en compte tout le contexte d'un mot en accordant à priori autant d'importance à des mots éloignés qu'à des mots proches, contrairement aux modèles récurrents qui faisaient l'état de l'art avant l'arrivée des Transformers, en 2016 (cf. Attention is All You Need, Google 2016 dans les références.)

- Le Transfer Learning, qui consiste à entraîner un modèle sur une tâche très générique (souvent non supervisée) sur un dataset gigantesque (par exemple le corpus de Wikipédia), puis à spécialiser le modèle en le modifiant sur une seconde tâche différente de manière supervisée et sur un dataset plus réduit.
De plus, leur contribution est aussi et surtout dans la méthodologie de pré-entrainement du modèle de langage (le premier modèle), qui se fait en combinant deux tâches génériques non supervisées:
- La complétion de phrases à trou, c'est à dire trouver le meilleur mot pour compléter une phrase du type: "je suis allé au __ ce matin pour acheter mes légumes".
- La prédiction de la prochaine phrase dans un texte.
Ces deux tâches peuvent s'effectuer grâce à un entraînement auto-supervisé sur des datasets gigantesques comme l'intégralité de Wikipedia, des corpus de sites crawlé ou à partir des réseaux sociaux publics (Twitter, Reddit ...). En passant en revue tous ces contenus, l'algorithme devient de plus en plus performant à déterminer les mots qui vont généralement ensemble en fonction d'un contexte assez large (de l'ordre de la phrase ou du paragraphe).
Qu'est-ce que ça change ?
Le gros changement apporté par BERT est cette idée de modèle de langage: la plupart des tâches de NLP ont en commun d'essayer de comprendre le contexte d'un mot et de trouver les relations entre les mots d'une phrase, et c'est ce que tente d'apporter le modèle de langage. Concrètement, cela signifie que pour n'importe quelle tâche de NLP, il suffit maintenant de réutiliser le modèle de langage pour avoir cette compréhension générale, puis de spécialiser la "tête" de l'architecture pour une tâche donnée.
La seconde conséquence est d'ordre pratique: avec un modèle comme BERT, l'entraînement d'un modèle sur une tâche spécifique se résume généralement à n'entraîner que la tête de l'architecture, donc à un coût dérisoire par rapport à un modèle complet comme précédemment.
Maintenant, il est devenu extrêmement facile d'utiliser et d'entraîner un modèle très performant pour toute une diversité de tâches de NLP. Cela a été grandement facilité par la publication du code et des modèles pré-entraînés, et par l'arrivée de Hugging Face, une entreprise de l'open source fondée par deux français qui propose une interface standard et un hub de modèles pour les transformers.
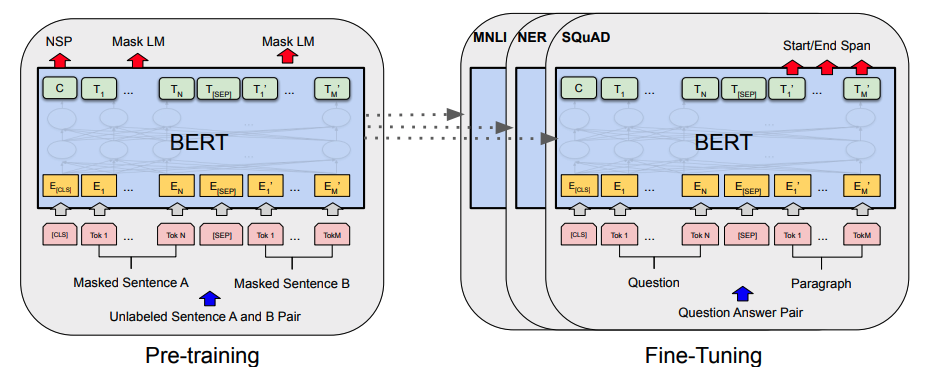
Utilisation des transformers
BERT et les autres transformers sont conçus pour être réutilisable en grande partie pour différentes tâches, il ne reste donc qu'à réadapter les entrées et sorties à la tâche visée. Nous allons regarder dans cet article le cas de la spécialisation et de l'utilisation d'un modèle de transformer pour une tâche d'extraction d'entités nommées (NER) à partir de différentes bibliothèques open-source de NLP.
La tâche d'extraction d'entités nommées: données et annotation
Le but de l'extraction d'entités nommées est de reconnaître dans un texte les mots ou ensembles de mots qui correspondent à des villes, pays, dates, langages de programmation, personnes ou tout autre catégorie pour lesquels on ne peut généralement pas lister l'ensemble des mots qui représentent ces entités.
Par exemple, dans la phrase "My name is Wolfgang and I live in Berlin", la tâche de NER devrait permettre d'extraction des mots “Wolfgang”, classés en tant que personne et “Berlin” comme ville.
Il s'agit en fin de compte d'une tâche de classification de token (un token est un mot ou une partie de mot), supervisée, et il y a plusieurs méthodes d'annotation des données. Nous allons présenter uniquement la méthode IOB, acronyme pour Inside, Outside et Begin, où chaque mot reçoit une annotation O ou I/B-[type d'entité]. Pour notre exemple cela donnerait ça:
My name is Wolfgang and I live in Berlin
O O O B-PER 0 0 0 0 B-CITYOu sur un second exemple:
I'm Yoann Couble and I write about Natural Language Processing in Python
O O B-PER I-PER O 0 O O B-TECH I-TECH I-TECH O B-LANGL'objectif de l'algorithme sera donc de déterminer pour chaque token l'annotation à positionner.
🤗 Hugging Face Transformers
Hugging Face a construit toute une API pour faciliter l'utilisation des transformers. La librairie propose des pipelines pré-définies et une bibliothèque de modèles explorables par tâches et langue et de datasets prêtes à l'emplois. L'avantage de Hugging Face est la grande diversité de modèles expérimentaux ou éprouvés qui sont disponibles sur le hub et la facilité d'utilisation et d'expérimentation qu'il permet.
La configuration d'un modèle se fait très facilement (sans code) à l'aide d'un fichier de configuration: https://huggingface.co/dslim/bert-base-NER/blob/main/config.json
{
"_num_labels": 9,
"architectures": [
"BertForTokenClassification"
],
"attention_probs_dropout_prob": 0.1,
"hidden_act": "gelu",
"hidden_dropout_prob": 0.1,
"hidden_size": 768,
"initializer_range": 0.02,
"intermediate_size": 3072,
"layer_norm_eps": 1e-12,
"max_position_embeddings": 512,
"model_type": "bert",
"num_attention_heads": 12,
"num_hidden_layers": 12,
"output_past": true,
"pad_token_id": 0,
"type_vocab_size": 2,
"vocab_size": 28996,
# Labels
"id2label": {
"0": "O",
"1": "B-MISC",
"2": "I-MISC",
"3": "B-PER",
"4": "I-PER",
"5": "B-ORG",
"6": "I-ORG",
"7": "B-LOC",
"8": "I-LOC"
},
"label2id": {
"B-LOC": 7,
"B-MISC": 1,
"B-ORG": 5,
"B-PER": 3,
"I-LOC": 8,
"I-MISC": 2,
"I-ORG": 6,
"I-PER": 4,
"O": 0
}
}
Ici l'architecture choisie est BertForTokenClassification ce qui correspond à notre tâche de NER. Et on retrouve aussi les différents hyper-paramètres des transformers (nombre de têtes d'attention, paramètres d'attention, ...). Pour pouvoir réutiliser les poids d'entraînement d'un modèle pré-entraîné, il faut faire attention à ne changer que ce qui ne casse pas la compatibilité avec le modèle pré-entraîné.
Dans ce notebook nous n'allons pas entraîner de nouveau modèle, mais utiliser directement le modèle qui a été entraîné avec la configuration présentée au-dessus.
%pip install --upgrade -q torch transformers "spacy>=3.2.0"
from transformers import AutoTokenizer, AutoModelForTokenClassification
from transformers import pipeline
model_name = "dslim/bert-base-NER"
# Récupération du modèle et d'un tokenizer adapté (peut prendre du temps car il faut télécharger le modèle qui est assez volumineux)
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForTokenClassification.from_pretrained(model_name)
# Définition de la pipeline
nlp = pipeline("ner", model=model, tokenizer=tokenizer)
example = "My name is Wolfgang and I live in Berlin"
ner_results = nlp(example)
ner_results
Notons que seuls les tokens classifiés avec une entité sont montrés, le reste a reçu une annotation "O".
Utilisation des transformers avec spaCy
spaCy est une bibliothèque open-source permettant d'industrialiser des applications de traitement du langage naturel. L'avantage de spaCy par rapport à Hugging Face est qu'il va être possible de mutualiser un même modèle de langage à base de transformers pour plusieurs modèles spécialisés pour différentes tâches sur un même document.
spaCy fournit également des modèles pré-entraînés et bien intégrés à spaCy. Ce sont les modèles finissant en _trf comme celui-ci basé sur camembert-base
Pour pouvoir l'utiliser, il faut télécharger le modèle dans le même environnement virtuel / kernel (dans mon cas, un environnement pyenv)
pyenv activate transformers_3.8.6
python -m spacy download en_core_web_trf
import spacy
from spacy import displacy
nlp = spacy.load("en_core_web_trf")
doc = nlp("My name is Wolfgang and I live in Berlin")
displacy.render(doc, "ent")
Une adoption qui s'étend maintenant au delà du langage
Nous avons pu voir et comprendre l'apport de BERT et des transformers au paysage du NLP, et l'impact des transformers continue de faire son chemin, avec la vision qui a eu tôt fait de les adopter (modèls VIT, VILT, CLIP etc.) ainsi que l'audio et la vidéo.
Maintenant, la recherche sur les transformers se plonge dans la convergence multi-modale (fusion Vidéo-Audio-Texte), avec notamment le très récent Data2Vec de Facebook AI Research cette année. Cela dit, le problème difficile de la compréhension du monde est loin d'être résolu, et la recherche continue d'être très active sur le sujet.
Ressources et rédérences sur le sujet
Références
- Attention is all you need (2016, Transformer paper): https://arxiv.org/abs/1706.03762
- BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding (2018): https://arxiv.org/abs/1810.04805
- Illustrated transformer: http://jalammar.github.io/illustrated-transformer/
- BERT model doc on hugging face: https://huggingface.co/transformers/model_doc/bert.html#bertmodel
- https://spacy.io/usage/embeddings-transformers
Exemples
- Exemple de configuration sur le hub de huggingface: https://huggingface.co/dslim/bert-base-NER/blob/main/config.json
- Transformers pour le NER FR https://huggingface.co/models?language=fr&pipeline_tag=token-classification&sort=downloads&search=ner
- Use huggingface transformers within spacy: https://reposhub.com/python/deep-learning/explosion-spacy-transformers.html